BI and AI Architecture Hero for Dynamics 365 with Azure Synapse

New article (August 2023) updated !
Hello the Community !
It was time for me to do a long blog post article about something really important about Dynamics 365 : How to deploy a global end-to-end Architecture for BI and AI/ML very quickly, with of course the Azure Data Platform : aka Data Lake and Synapse Analytics. After several deployments, and of course several best practices and projects, time to share my thought about this and help you deploy a real Modern Data warehouse with all kind of Business Apps data you have ! Let’s jump in !
So…. how to begin ? Well, globally you have seen it was one of my favorite topic. I created for couple of months several topics on this subject, which is for me the most important thing when you deploy a Dataverse/Power Platform/CRM projects and of course even mandatory in case of ERP on Dynamics 365.
Time for me to update a little bit in 2022, how to deploy very fast a global Architecture for DATA !
Data is the essence of the 21st century, it’s everywhere, how to operate/work on it correctly, in real-time?
You may wonder: “OK, I have tons of data in my - ERP, CRM, Dataverse- I want to visualize it very quickly in my Power BI or build your own AI Builder model or Azure ML - even via Azure Auto ML”
Enough talking, let’s jump in on how to do that :)
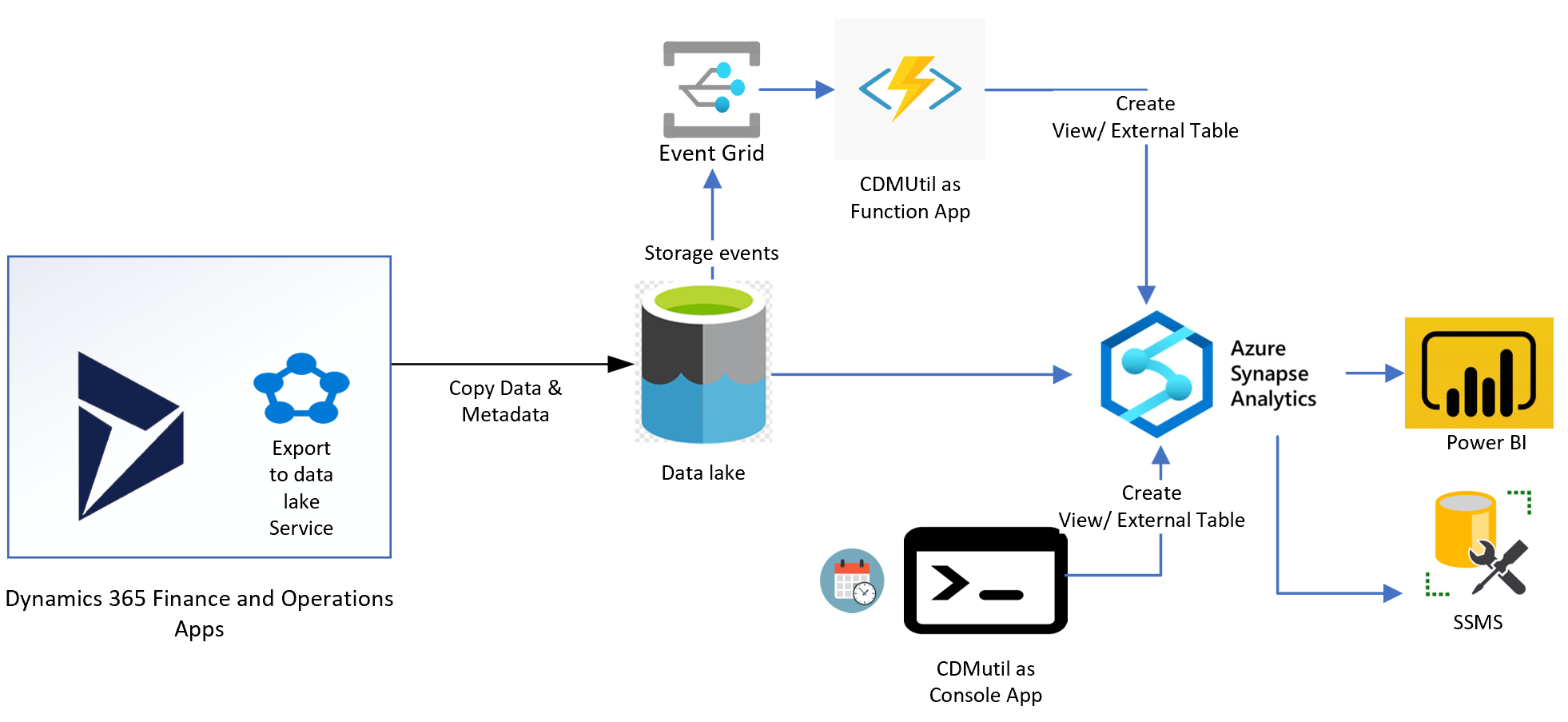
For Dynamics 365 / Power Platform / Dataverse side
You have maybe noticed in the end of 2021, Microsoft released a new way to do all in 1 step everything connected, aka Microsoft Azure Synapse Link
This wizard is very well achieved and help you in just a few minutes to deploy your end-to-end BI architecture for Dataverse data (also at a very low cost, but we talked about this topic at the end of the article)
Go to your Dataverse system : Maker Portal like me :

I will not explain again how to create a quick Azure Data Lake (if you still need you can check on Microsoft Docs here), the only thing important here is to deploy in the same region of your Dataverse!
You will also need just to create an Azure Synapse Analytics Workspace, that’s it. (no SQL Pool dedicated, just Serverless mode) + globally in the same Azure Resource Group of your Data Lake.
The new thing here is you create the link between your Data Lake and also your Serverless Synapse Analytics in just few clicks !

You can after select the tables you want.
All those tables will be pushed after with an initial sync and after that in “near” real-time in the DataLake.

Remember, Azure Data Lake is “just” a storage account, to store big data. Currently, it will export in real time in CSV files with a .json metadata file attached. (also known as CDM)
Globally, will be great to have the possibility in the future to use PARQUET files. Which is even better than CSV files (carriage returns, file size, compression etc..)
Also remember, the cost of a storage account is very cheap.
At the end, if you go to your Data Lake, you will see that :

All files are partitioned month to month. Better for performance after via Synapse.

Model.json at the root folder is very the master file to store the metadata properties. And sub model.json for every table can be found here :

Globally that’s it for Data Lake, now let’s go to Synapse. Since you have flagged to link it (that’s the purpose of this new feature) every tables have been generated for you as External Tables

This feature create for you a “Lake Database” - or also called Data Lakehouse. Data stay in your data lake, table can request directly via TSQL from Apache Spark behind. Serverless mode, no SQL database provisioned for you.

Source : Microsoft
Microsoft will in the future add database templates from different types of industry. That will help you to cross-data too from external system within your dataverse system !

Technically speaking, each tables are made as external table, and if you go via SQL Server Management Studio (SSMS), and script table “CREATE TO”, you’ll find behind how it has been created. 3 elements :
External Table with LOCATION
External Data Source
Externa File Format

Of course, you can do TSQL query in realtime because it’s directly connected to the Data Lake, and this one is always keeping up-to-date from the Dataverse side.
Now we have all data in Synapse Serverless, well : that’s good, what are the next steps ? :)
The first thing for me is : now you have some work to do! Globally, it’s not the end, 1st part is really easy to set up as you have seen, but you need to build extra custom views (joins, group by etc…). Indeed, at the end if you want to publish PowerBI Datasets, it’s often complex for end users to learn the data model behind. So that’s why, I really suggest to do all the data model in Synapse and will be shared via datasets in PBI. These datasets can also be a good way to add RLS (Row Level Security), Security Roles, DAX Queries or other PowerBI stuff, but that’s it.
As already talked in my book, AI is also everywhere now.
Here in Synapse Lake Database, you can start creating your Azure Automated ML. Of course you can also see that you can build Notebook in Python based on dedicated Apache Spark Cluster with Databricks, but that’s it more for advanced ML ;)

Here you can choose 3 types of model of Azure Automated ML.

If I Pick Regression as an example on opportunity, I can predict the totalamount expected. For that again I will need still an Apache Spark Cluster to run the Azure Automated ML. But globally that’s it.

To summarize on the Dataverse side, you have seen the straitgh forward capability of all connected Microsoft ecosystems.
I’ll also explain why you have chosen that ?
1s point is: Azure SQL export will be down in 2022. OData direct connection in PowerBI - you don’t do a real data warehouse and also, huge performance issues and power platform limits on API call. Last, you have also the TSQL read-only endpoint, which is fine, but let’s assume you want those features explained before? Let’s assume you want also to build some dataflows (ETL/ELT), some interfaces, some automatic extractions, pipelines, integrations, or other kinds of stuff you can on Synapse. This final part, it will be at the end of this article if you want more real examples. But somehow, you will be blocked at some point if you pick only TSQL Endpoint on Dataverse.
Also, what if I have (like me) a Finance Operations instance to cross-data between CRM and ERP data?
Good transition, because it’s exactly what I will explain now :)
For Dynamics 365 Finance Operations
So.. for D365 FinOps, how can we achieve the same thing.
1st thing, I’ll suggest to read this article from Microsoft which explain the How-To completly - including the installation part.
Last but not least, very important, download the CDMUtil Solution from Microsoft Fast Track in Github here :
I’ll assume that you have successfully installed the Azure Data Lake addin in LCS for your instance. For that, keep in mind that this feature is globally new and a lot of improvements will come surely in a few months. As of now, real-time is only for sandbox, production will come in short weeks (public preview). You can still accept that or ask Microsoft to enable you this - even for production use.
UPDATE 1st of June 2022 : Real-Time is now in GA (even Production)
Otherwise, if you don’t want change feeds feature in realtime - for production, the refresh is 4 times per day (meaning every 6 hours)

When it’s installed, you can go directly here in Export Data Lake (I always use the search nav bar in top)

Here you can see all my running tables from my ERP. I can activable whatever tables (row data) I want ! And also I can activate Data Entities too ! Which will help you somehow after in Synapse link. (you’ll see after)
Well globally that’s it on F&O side.
If you go the Data Lake, it’s very similar as explained before for Dataverse side.

You have a root folder for Finance Operations, just near the same root folder for Dataverse.
For Finance Operations, you have after sub-folders per environment. And right after multiple folders, and the most important one: Tables
In tables, you have multiple folders per module of the ERP. And finally, an important file for the CDMUtil Solution called: Table Manifest CDM.json
As explained with Dataverse, it’s CDM-friendly mode, meaning all tables have a metadata properties file (JSON file) and CSV files split by partition. In F&O it’s not by month, but by the amount of the file size. Again not parquet mode, damned… :)
Every time, new or updated data will happen in F&O, CSV data will be up-to-date too. Like same thing in Dataverse.

The problem for me is: those CSV files can have carriage return on some field! That’s bad, so that’s why parquet mode will be better (including also a file size much smaller than CSV). Let’s assume you don’t want Azure Synapse and you have already a Data Platform with AWS or GCP, if you want to push & sync those CSV in AWS S3 Data Lake, you’ll have to do some manipulations after. But we will stay on Azure, that’s better and Synapse will take care of it in Serverless mode.
Now that I have my data in my Data Lake (the same as Dataverse), I’m quite happy, but of course, it’s not the end… Let’s go on the Azure Synapse part now.
So, contrary to Dataverse, for F&O you don’t have a direct wizard to enable Azure Synapse Link. You have to execute the tool CDM Util from Fast Track team. Thanks by the way for their huge work behind, and this tool is very often updated!
Source : Github FastTrack team
On my side, I’ll pick the Console App, so that I can execute this tool whenever I need, but you can activate also the Event Grid + Azure Function so that whenever a key user extracts new tables in D365 F&O, it will be created as External Table in Synapse Serverless automatically!
Views can be also created via this tool to reflect a Data Entity (which you know is somehow an aggregation of multiple tables in FinOps with some join queries etc…)
The only problem I have seen on this tool is : the nvarchar with a size of 100 by default. For some fields it’s not enough, so after creating the External Table you’ll have to script (DROP/Create to) to change and put something much bigger : otherwise you’ll have some errors after doing a TSQL request.
To execute, you have to change globally the config file. On the github doc readme, all parameters have been well explained. Like this :

To explain a little more for you and with multiple executions. I can say :
TenantId , AccessKey : quite simple
ManifestURL : put the direct link of the Table Manifest Json file on top as I explained before
TargetDB : put the SQL Synapse On-Demand (serverless) link ! And also, pick a new Database name you want ! - it will be auto-created for you.
ProcessEntities can be good if you want Data Entities as views. Pick also DDLType to SynapseTable .
You can check but globally all tables will be there in a few seconds.

Again, it’s external table, that means that TSQL query will be executed on top of Data Lake data on it - via Apache Spark motor (like dataverse same thing)
Even more important than Dataverse, for F&O, as you know the data model is not easy to learn. So building custom views will be really a mandatory part for me
(Purchase Analysis, Inventory Analysis, Finance etc….)

Again as you can see below, for this table “AssetBook”, you have the datasource (location of the file with a wildcard path because in the future you can have multiple CSV files behind) - the file format. Be aware that the user can connect to Synapse Serverless with SQL authentification but also via their Azure AD Account which will need also that this user as Storage Blob Data Reader on the Data Lake - otherwise you’ll have some credential issue doing some TSQL Request: normal because Synapse Serverless is just a mirror of your Data Lake. You can build custom security roles on certains schema , giving access on few tables for certain IT users.
Last but not least, now you can imagine doing some cross-data queries between these 2 databases (Dataverse <=> ERP) on Synapse!
Just important, the collation of the databases can be not the same between the one from F&O and the one from Dataverse, that’s another thing maybe to improve in the future.
But globally that’s it again for F&O side.
PowerBI Incremental refresh and Hybrid Tables
Now we have all things we need in Synapse Serverless, let’s jump to the end: Power BI of course.
1st thing, you have been maybe noticed in December 2021, Microsoft published a new way called: Hybrid Tables.
That will help to join both worlds: Direct Query and Import Data.
I will pick a real example in F&O side. Let’s assume I build some PBI Reports and Datasets and very large table - it’s often the case !
Serverless you’ll pay as TB of data processed. And even if Apache Spark is good in terms of performance, especially after doing multiple same requests in cache, it’s not really good to import more millions of rows every hour to refresh completely the reports. Maybe only few rows have been modified !
Since you are already end-to-end between F&O => Data Lake <= Azure Synapse in real-time : why not for PBI too ?
Of course, you can try to use Direct Query still, but sometimes some features are not supported with this mode. So I often pick import data every time. But, with Hybride table and incremental refresh, you can ask PowerBI to just archive old past data and incrementally refresh the recent data only ! That’s a huge improvement and performance/cost effectiveness!
Like here I pick my table, and the 3 dots to enable it. It’s OK with PowerBI PRO license and also Premium if you need Direct Query realtime.
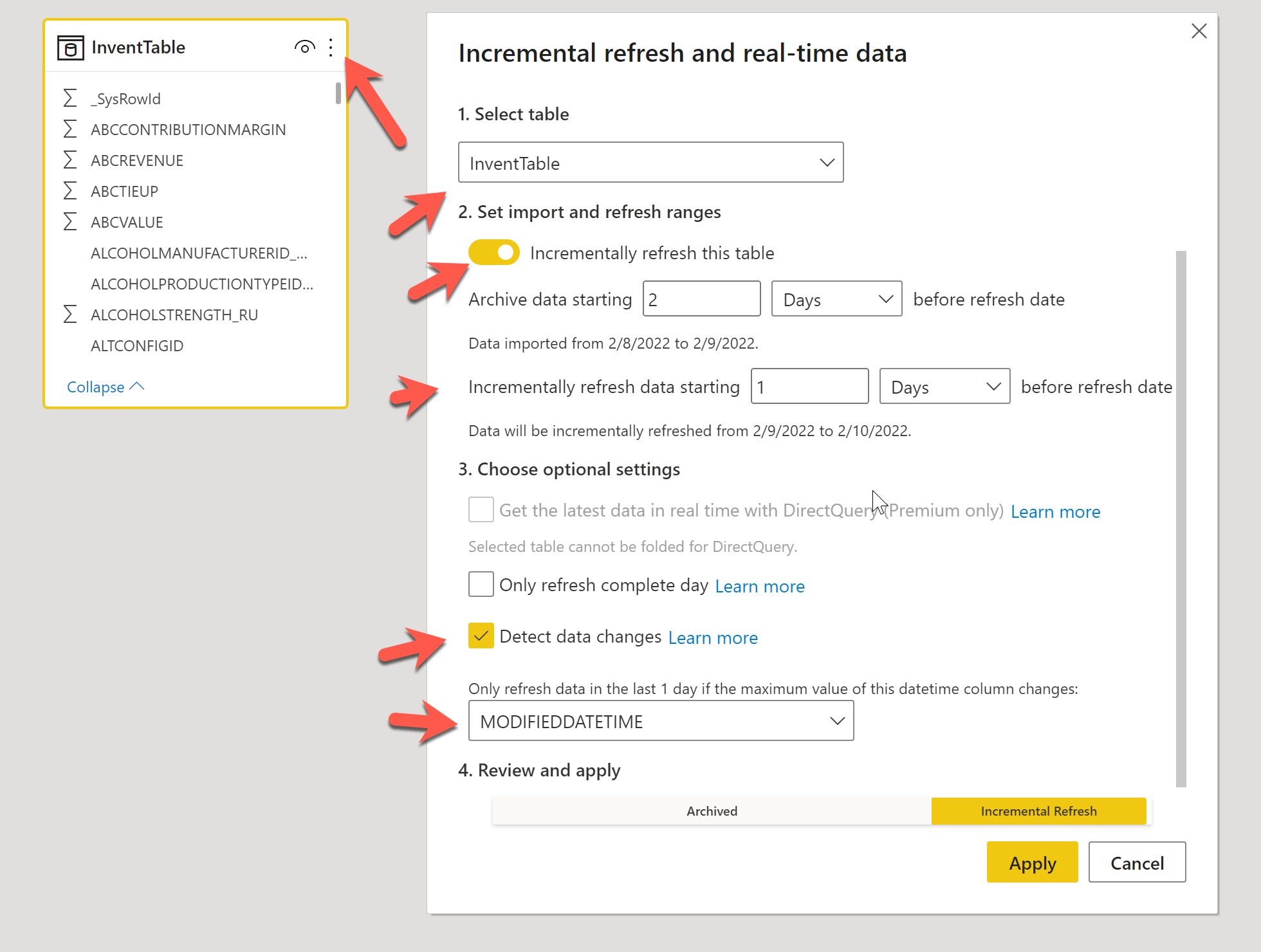
Since you have always modifieddatetime field and also SysRowId, you can really take advantage of that and avoid doing so many queries/data processed for nothing :)
The refresh time of data in PBI datasets will be better. That’s also a good way to say that Power BI Premium per User is for me a really good option to try.
On benchmark, I often decrease by half the time to refresh with this option.
I’ll not going deeper on that part, because I know that PowerBI MVP can really explain you much better than me all optimisations you can have with this option.
Pricing and Serverless vs SQL dedicated Pool
Pricing is very low, you can also activate some limits if you want. But again if you have done correctly the incremental part of PowerBI that will help you on that point. (data processed)


Also, compare to dedicated Pool and some benchmarks, queries are almost same time to execute, but also you’ll avoid to replicate data between Data Lake and Synapse, doing some pipelines, synchronization etc… Also the amount of time to build your own dedicated pool is very large, and the price too…
Synapse as a whole (data flow, interface etc…)
And yes Synapse is not only for BI or even AI like we have seen before, but also a good way to do some interfaces!
Let’s imagine I want to send automatically CSV files from a SQL Request (from my Dataverse or F&O data) - I can build that in Synapse of course.
Build pipelines, build datasets, do some dataflow if you need complex transformations and export it to a Blob Azure or Sharepoint and call a Power Automate flow to send it automatically by email or something else. That’s just 1 example, but globally my Synapse is my heart of all my data, so that’s even a good way to avoid doing to much developpments within the ERP and decrease the performance !

Conclusion
That’s it for today, hope you like this article, and feel free to share or comments you have questions or remarks, I’ll be happy to respond !
Aurelien
And video just for you :